Quick answer: For EV charging software, choose between large and small language models by workload, not by which is smarter. Use SLMs for high-volume, narrow, edge, or latency-sensitive jobs like OCPP fault classification and on-site monitoring; use LLMs for open-ended, low-volume reasoning like test generation and support chat. Most production systems use both.
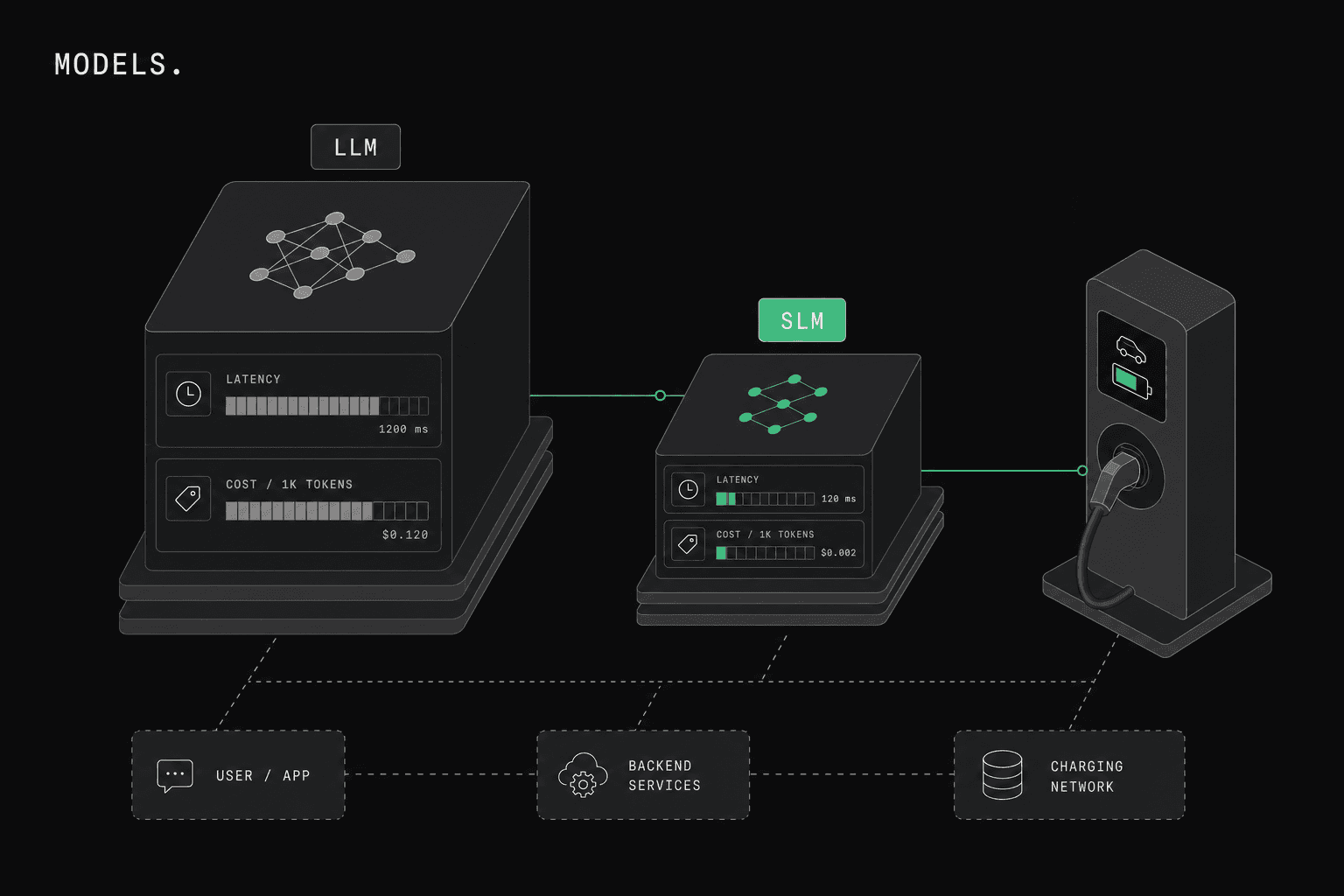
A large language model (LLM) is a general-purpose model with broad reasoning, usually run in the cloud. A small language model (SLM) is a compact model, often a few billion parameters or fewer, that can run on cheaper hardware or at the edge and is tuned for a narrower job. For EV charging software, picking between them is not about which is smarter. It is about where the work runs, how often it runs, and what data it touches.
This guide gives you a decision framework instead of a winner, because the right answer changes by workload.
Quick answer
| Workload | Better fit | Why |
|---|---|---|
| OCPP fault classification at scale | SLM | High volume, narrow task, latency and cost matter |
| Real-time monitoring at the charger or site | SLM | Runs at the edge, works offline, predictable cost |
| Structured extraction from OCPP or OCPI logs | SLM | Pattern is narrow, output is constrained |
| Test scenario generation from a spec | LLM | Needs broad reasoning and context |
| Complex agent reasoning over conflicting signals | LLM | Hard tradeoffs, low volume, accuracy over cost |
| Operator and driver support chat | LLM | Open-ended language, varied questions |
Most production systems end up using both. The pattern is at the end of this guide.
Why does model size matter in EV charging?
Four pressures push EV charging workloads toward smaller models more than a typical SaaS app does:
- Scale. A network with thousands of chargers generates a constant stream of OCPP events. If every StatusNotification triggers a cloud LLM call, the bill and the latency add up fast. A narrow classification at that volume is an SLM job.
- The edge. Charging sites have local controllers. Running a small model on-site means smart charging and monitoring decisions keep working when the network link to the cloud is slow or down.
- Latency. Some decisions are close to real time. A round trip to a large cloud model adds delay an edge SLM avoids.
- Data privacy. Charging and energy data can be sensitive and regionally regulated. Keeping inference on-prem or in-region with an SLM avoids sending raw session data to a third-party model endpoint.
When should you use an LLM?
Reach for a large model when the task is open-ended and the volume is low enough that cost per call is not the constraint:
- Generating OCPP test scenarios from a protocol spec or a release diff.
- Diagnosing a novel fault where the reasoning has to span several systems.
- Operator-facing support that answers varied, unscripted questions.
- Any step where being wrong is expensive and you would rather pay for accuracy.
LLMs are also the faster path during development. Prototype the behavior with a capable model first, then decide later whether a smaller model can do the narrow version in production.
When should you use an SLM?
Reach for a small model when the task is narrow, the volume is high, or the work has to run at the edge:
- Classifying OCPP faults into known categories.
- Extracting structured fields from OCPP frames or OCPI CDRs.
- On-site monitoring that flags anomalies in MeterValues or session patterns.
- Routing: deciding which requests are simple enough to answer locally and which to escalate.
SLMs give you predictable cost, lower latency, offline operation, and tighter data control. The tradeoff is range: a small model handles the job it was tuned for and little beyond it.
How should you route requests between an SLM and an LLM?
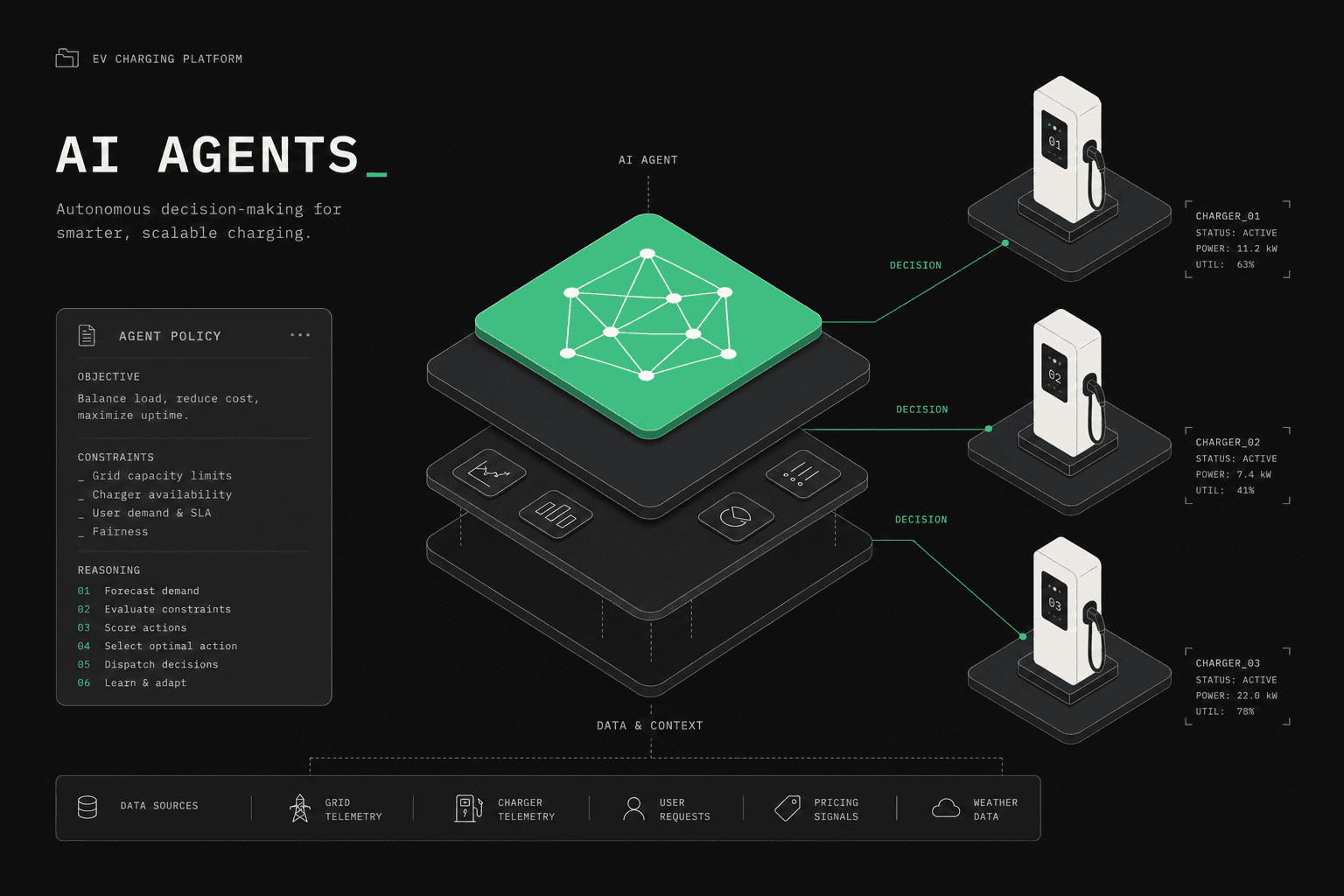
The most resilient designs do not choose one model. They use a small model as a router and a large model as the fallback — an approach that echoes NVIDIA Research's 2025 position paper on small language models in agentic systems, which argues for heterogeneous systems that mix small and large models.
- An SLM at the edge handles the high-volume, narrow steps: classify the fault, extract the fields, decide severity.
- When the SLM is uncertain, or the case is complex, it escalates to an LLM in the cloud.
- The LLM handles the long tail, and its answers can become training data that makes the SLM better at the next round.
For an EV charging network this means most OCPP events are handled locally and cheaply, and only the hard cases pay for a large model. It also means the system degrades gracefully: if the cloud link drops, the edge SLM keeps the lights on.
Worked example: OCPP fault triage
Say you want to triage every StatusNotification with an error across a 5,000-charger fleet.
- An LLM-per-event design is accurate but slow and expensive at that volume.
- An SLM tuned on your historical OCPP faults classifies the common cases in milliseconds, on-site, for a fraction of the cost.
- The handful it is unsure about escalate to an LLM that reasons across the full session and roaming context.
You get cloud-grade quality on the cases that need it and edge economics on the cases that do not.
Where does the training and evaluation data come from?
A small model is only as good as the examples you tune and test it on, and real fault data is scarce by definition. You cannot wait for 5,000 chargers to fail in interesting ways.
This is where an OCPP emulator earns its place. Generate labeled OCPP and OCPI sessions, including the rare failure modes, by running virtual chargers through scripted scenarios. Use them to tune the SLM and to build a held-out evaluation set that reflects real protocol behavior rather than synthetic prompts.
How do you evaluate a model for charging workloads?
Benchmarks built for general chat do not tell you whether a model handles OCPP. Evaluate on the work:
- Build a test set of real and emulated OCPP or OCPI scenarios with known correct outcomes.
- Run each candidate model (LLM and SLM) against it.
- Score on the metric that matters for the task: classification accuracy, extraction correctness, or, for agents, whether the resulting action was right and safe.
- Compare cost and latency at your real volume, not at demo volume.
OCPPLab gives you the environment for steps 1 and 3: virtual charger fleets across OCPP 1.6 and OCPP 2.0.1, reproducible failure scenarios, and the ability to run model-driven behavior against them at scale.
Bottom line
Use an LLM for open-ended reasoning, test generation, and support. Use an SLM for high-volume, narrow, latency-sensitive, or privacy-sensitive work at the edge. For most EV charging networks the answer is both, with a small model routing and a large model catching the long tail. Whichever you pick, validate it against chargers that behave like the real thing before it runs your network.
Start your testing or explore CPMS testing use cases.